Machine Learning from Human Preferences
Chapter 2: Learning
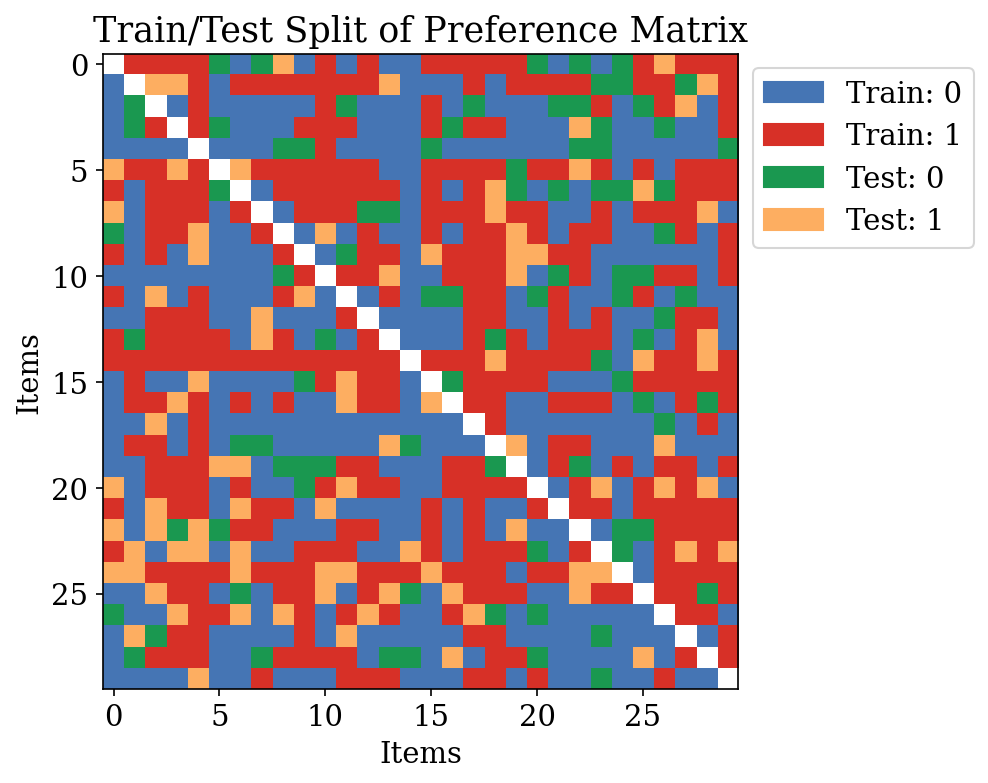
Train/Test Split for Preference Data
- Randomly partition observed pairwise comparisons: 80% train / 20% test
- For preference data: partition comparisons (not items) into splits
- Each entry: \(Y_{jj'} \in \{0, 1\}\) — whether item \(j\) beats item \(j'\)
MCMC Trace Plot and Posterior
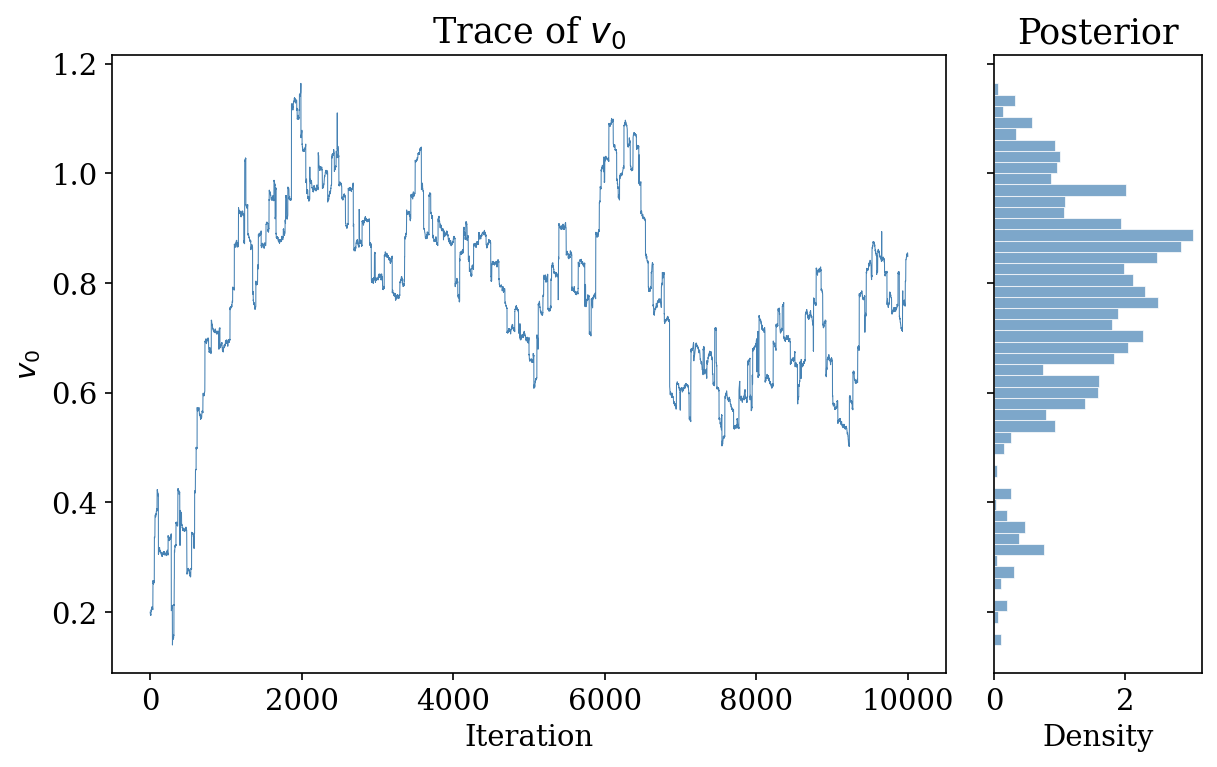
- Left: trace of \(v_0\) over MH iterations (good mixing)
- Right: marginal posterior histogram for \(v_0\)
- Posterior provides credible intervals for each item’s utility
GP Posterior with Confidence Intervals
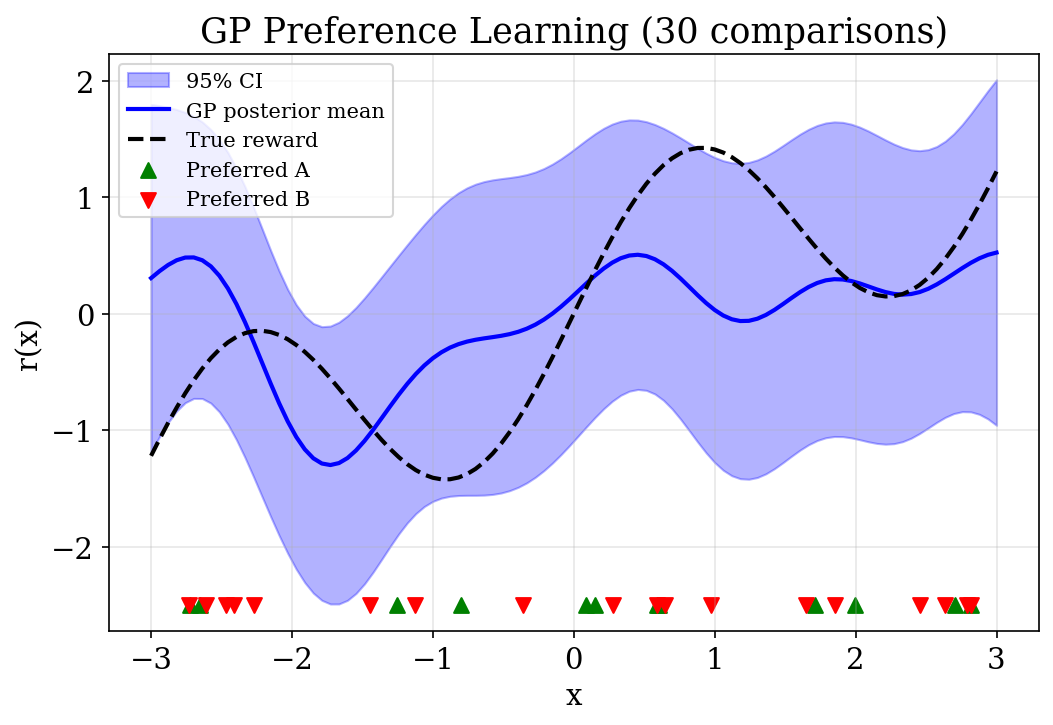
- GP recovers nonlinear reward from pairwise comparisons
- Uncertainty is wider where data is sparse
- True reward (dashed) lies within the 95% confidence band
Early Stopping
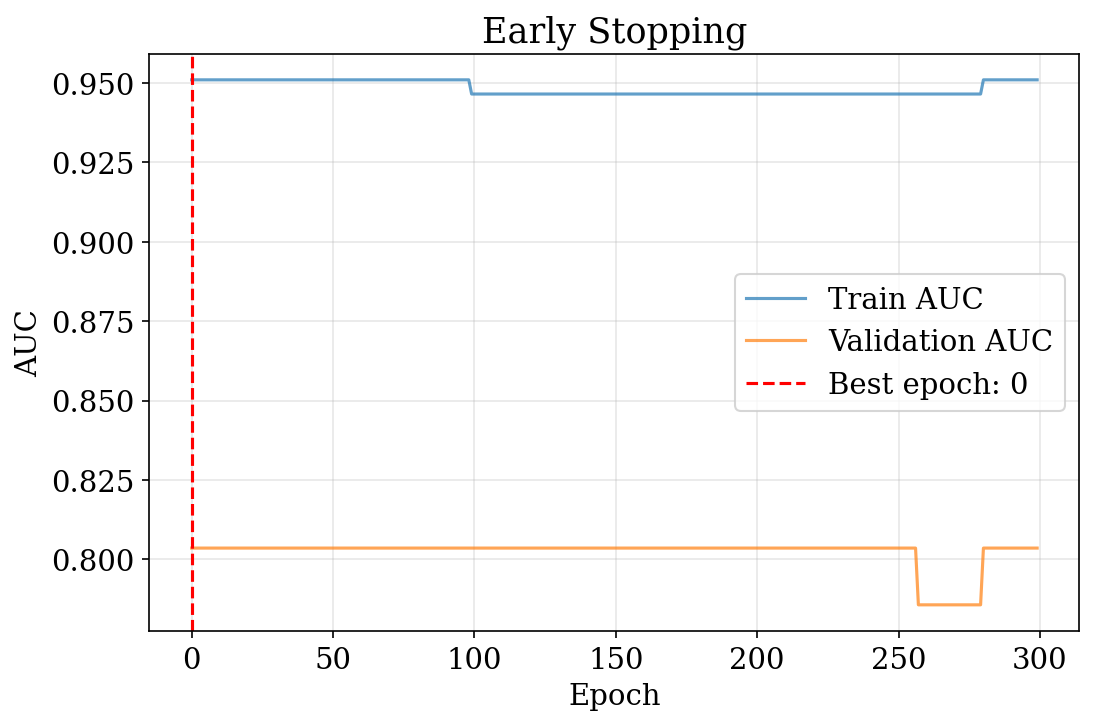
- Alternative to explicit regularization: stop when validation performance peaks
- GD follows a path from simple to complex models
- No hyperparameter \(\lambda\) to tune, but requires validation data
Hyperparameter Tuning with CV
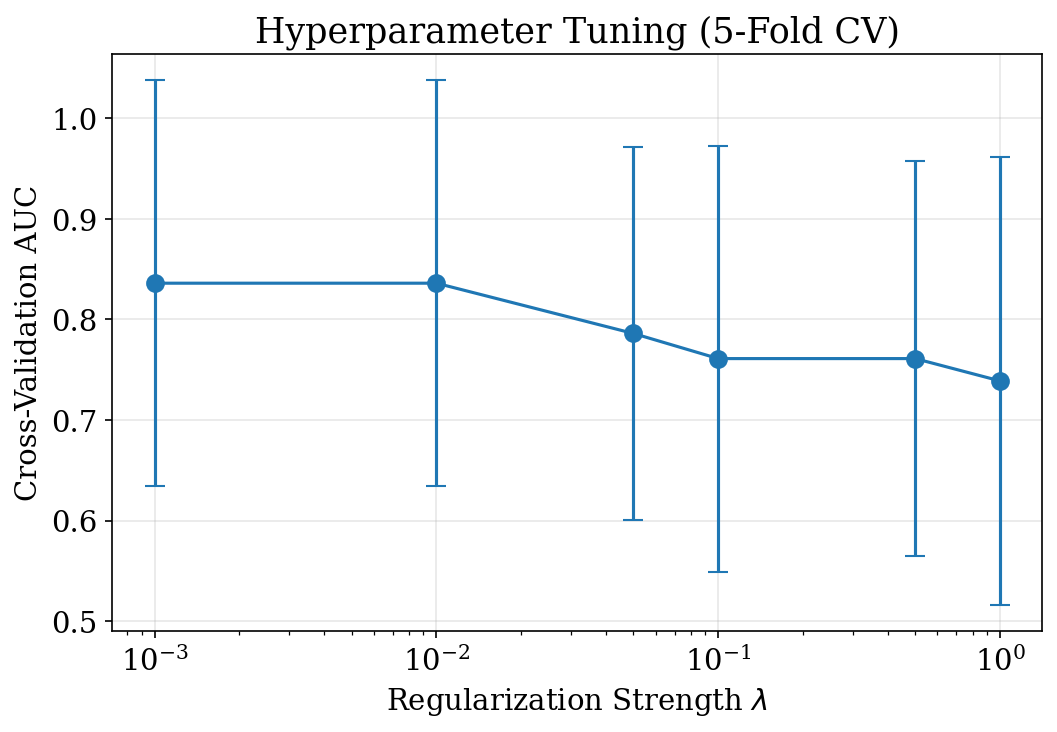
- Grid search over \(\lambda\) values using 5-fold CV
- Select \(\lambda\) with highest mean CV AUC
- Error bars show standard deviation across folds
LLM Preference: Method Comparison
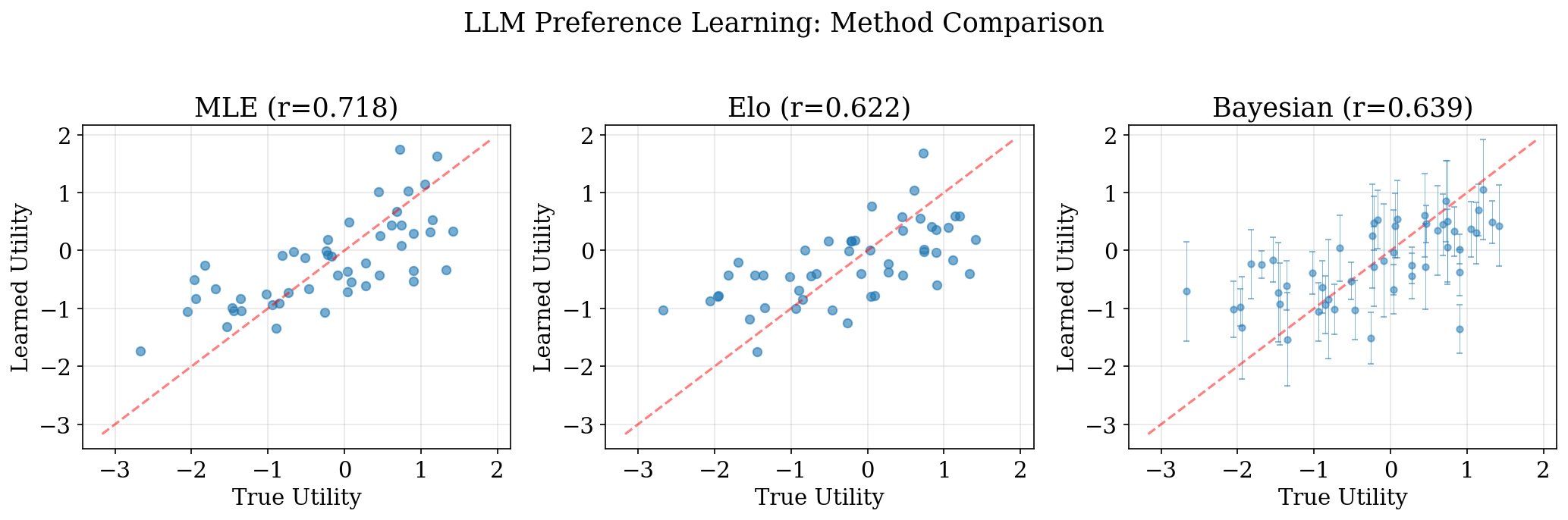
- All three methods successfully recover utilities correlated with ground truth
- Bayesian provides credible intervals (error bars); MLE and Elo give point estimates
References
- Bradley and Terry (1952)
- Elo (1978)
- Kingma and Ba (2014)
- Rafailov et al. (2023)
- Christiano et al. (2017)
- Additional:
- Herbrich, Minka, and Graepel (2006)
- Hunter (2004)
- Caron and Doucet (2012)
- Murphy (2012)
- Hastie, Tibshirani, and Friedman (2009)
![]()
Bradley, Ralph Allan, and Milton E Terry. 1952. “Rank Analysis of Incomplete Block Designs: I. The Method of Paired Comparisons.” Biometrika 39 (3/4): 324–45.
Caron, François, and Arnaud Doucet. 2012. “Efficient Bayesian Inference for Generalized Bradley-Terry Models.” Journal of Computational and Graphical Statistics 21 (1): 174–96.
Christiano, Paul F, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei. 2017. “Deep Reinforcement Learning from Human Preferences.” Advances in Neural Information Processing Systems 30.
Elo, Arpad E. 1978. The Rating of Chessplayers, Past and Present. New York: Arco Publishing.
Hastie, Trevor, Robert Tibshirani, and Jerome Friedman. 2009. The Elements of Statistical Learning: Data Mining, Inference and Prediction. 2nd ed. New York: Springer.
Herbrich, Ralf, Tom Minka, and Thore Graepel. 2006. “TrueSkill: A Bayesian Skill Rating System.” In Advances in Neural Information Processing Systems, 19:569–76.
Hunter, David R. 2004. “MM Algorithms for Generalized Bradley-Terry Models.” The Annals of Statistics 32 (1): 384–406. https://doi.org/10.1214/aos/1079120141.
Kingma, Diederik P., and Jimmy Ba. 2014. “Adam: A Method for Stochastic Optimization.” arXiv Preprint arXiv:1412.6980.
Murphy, Kevin P. 2012. Machine Learning: A Probabilistic Perspective. Cambridge, MA: MIT Press.
Rafailov, Rafael, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, and Chelsea Finn. 2023. “Direct Preference Optimization: Your Language Model Is Secretly a Reward Model.” https://arxiv.org/abs/2305.18290.