Machine Learning from Human Preferences
Chapter 2: Choice Models (Part 1)
Overview
- Tools to predict the choice behavior of a group of decision-makers in a specific choice context.
- Thurstone research into food preferences in the 1920s.

Application: Marketing
- Marketing: Predict demand for new products that are potentially expensive to produce
- What features affect a car purchase?
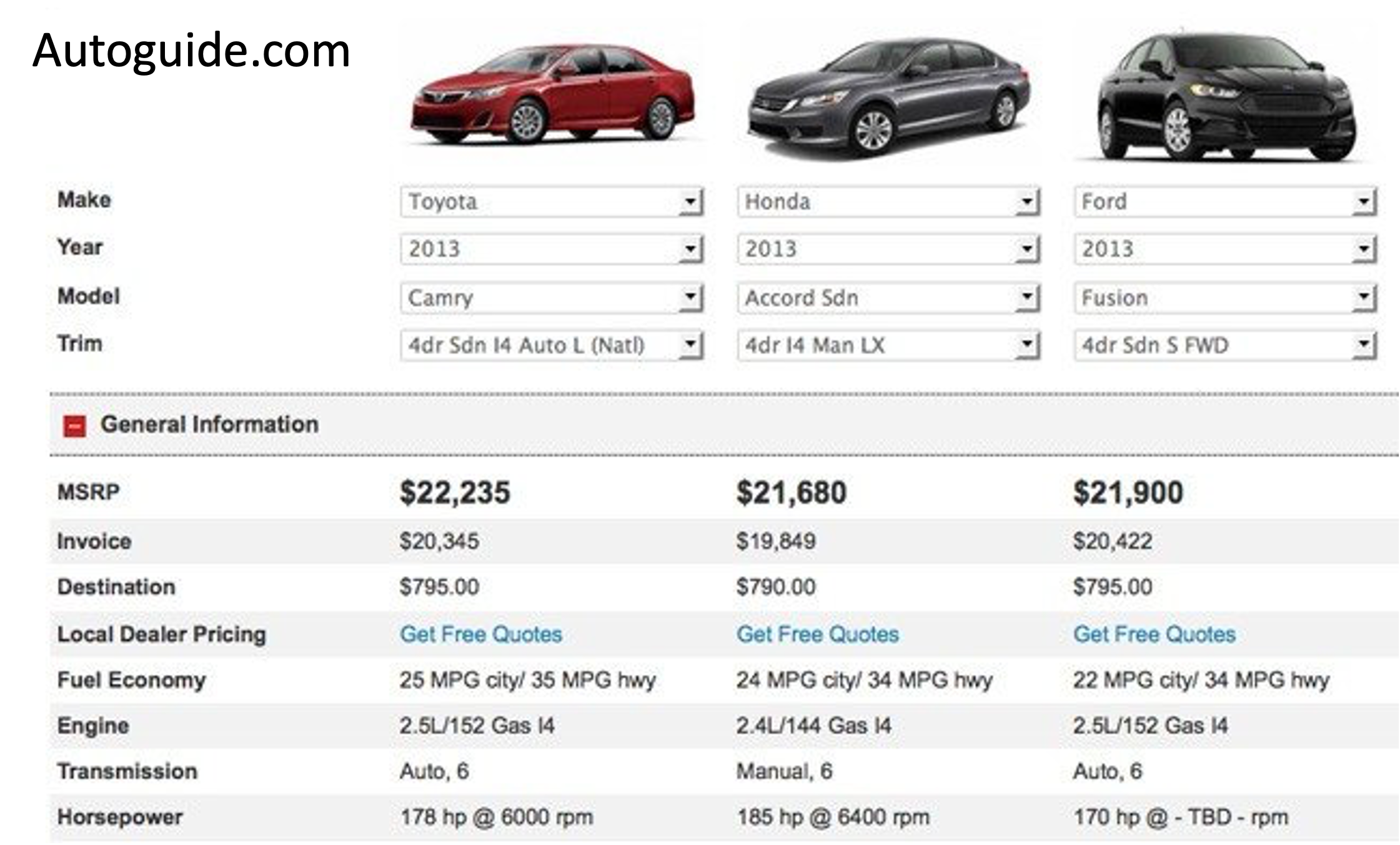
Application: Economics
- Microeconomics: Random Utility Theory (1970s) (McFadden: 2000 Nobel prize for the theoretical basis for discrete choice)
- Energy Economics:
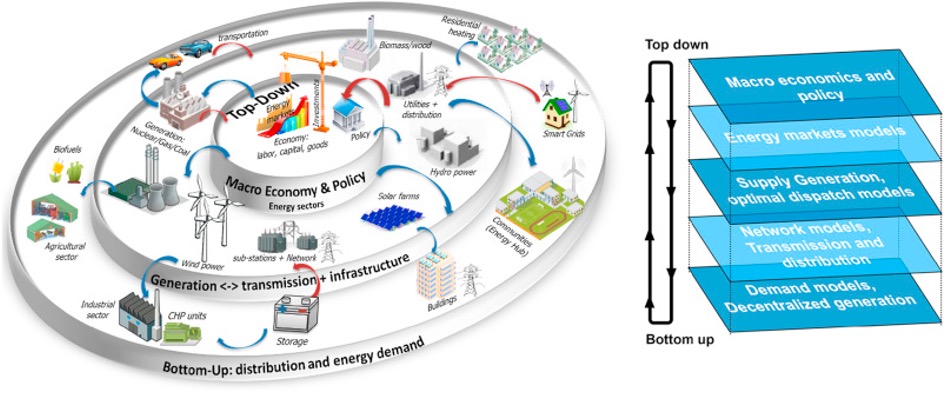
Del Granado et al. (2018)
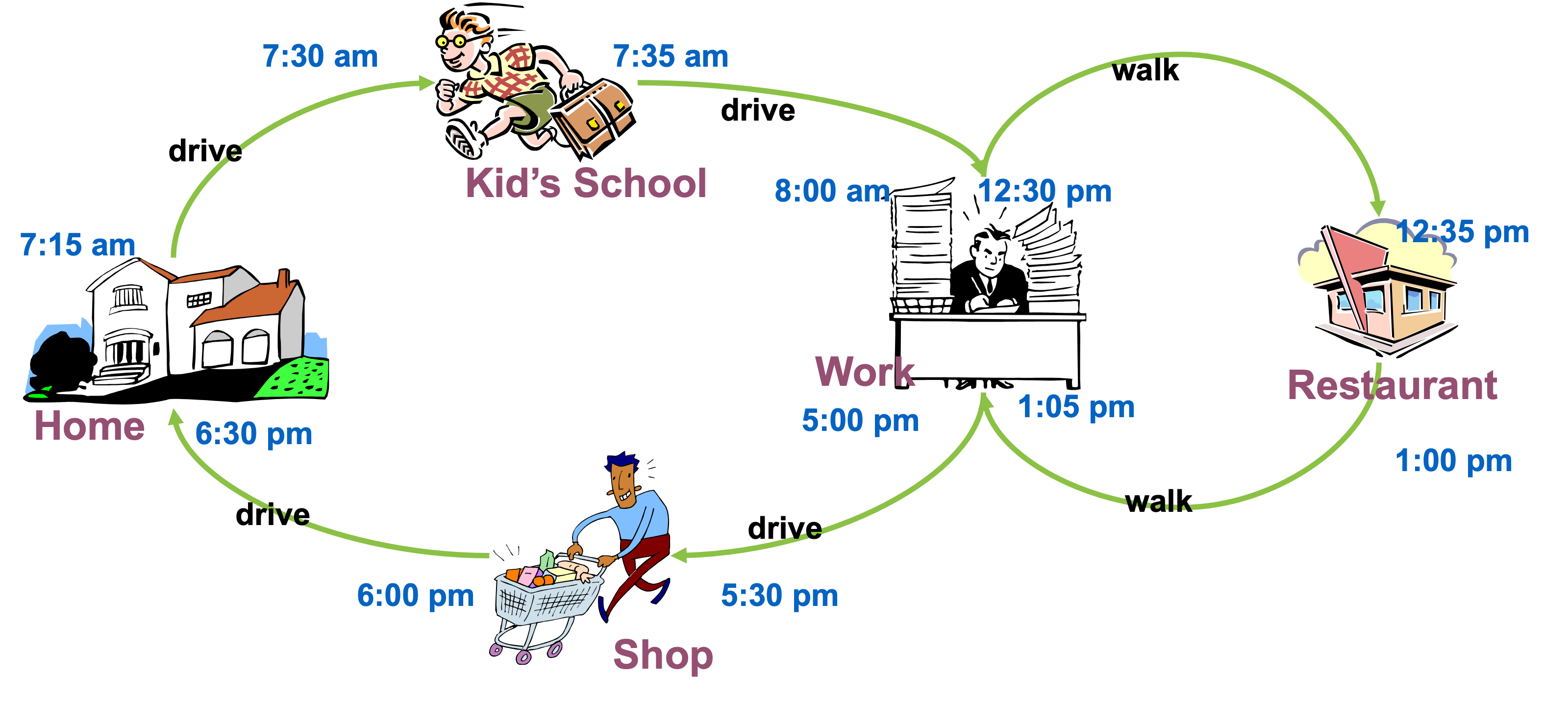
Example: Daily activity-travel pattern of an individual. Source: Chandra Bhat, “General introduction to choice modeling”
Application: Transportation
- Transportation: Predict usage of transportation resources, e.g., used by McFadden to predict the demand for the Bay Area Rapid Transit (BART) before it was built
- How pricing affects route choice
- How much is a driver willing to pay
Image source: supplychain247.com
Application: RL and Language
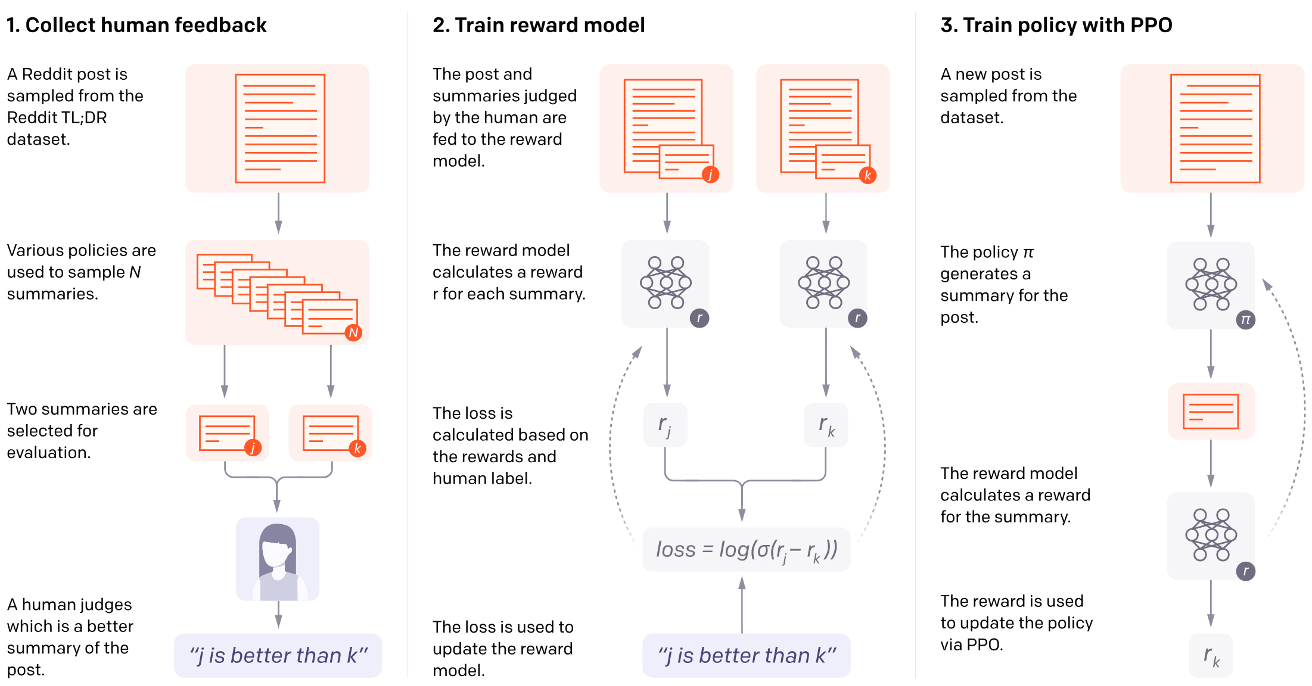
https://openai.com/research/learning-to-summarize-with-human-feedback
References
- Train (1986)
- McFadden and Train (2000)
- Luce et al. (1959)
- Additional:
- Ben-Akiva and Lerman (1985)
- Park, Simar, and Zelenyuk (2017)
- Rafailov et al. (2023)
![]()
Ben-Akiva, Moshe E., and Steven R. Lerman. 1985. Discrete Choice Analysis: Theory and Application to Travel Demand. Transportation Studies. Cambridge, MA: MIT Press.
Del Granado, Pedro Crespo, Gustav Resch, Franziska Holber, Marijke Welisch, et al. 2018. “Modelling the Energy Transition: A Nexus of Energy System and Economic Models.” Energy Strategy Reviews 20: 229–35.
Luce, R Duncan et al. 1959. Individual Choice Behavior. Vol. 4. Wiley New York.
McFadden, Daniel, and Kenneth Train. 2000. “Mixed MNL Models for Discrete Response.” Journal of Applied Econometrics 15 (5): 447–70.
Park, Byeong U, Leopold Simar, and Valentin Zelenyuk. 2017. “Nonparametric Estimation of Dynamic Discrete Choice Models for Time Series Data.” Computational Statistics & Data Analysis 108: 97–120. https://doi.org/10.1016/j.csda.2016.10.024.
Rafailov, Rafael, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, and Chelsea Finn. 2023. “Direct Preference Optimization: Your Language Model Is Secretly a Reward Model.” https://arxiv.org/abs/2305.18290.
Train, Kenneth. 1986. Qualitative Choice Analysis: Theory, Econometrics, and an Application to Automobile Demand. MIT Press.