Machine Learning from Human Preferences
Chapter 1: Introduction
Overview
We focus on statistical and conceptual foundations and strategies for interactively querying humans to elicit information that improves learning and applications.

Overview
This class is not exhaustive!
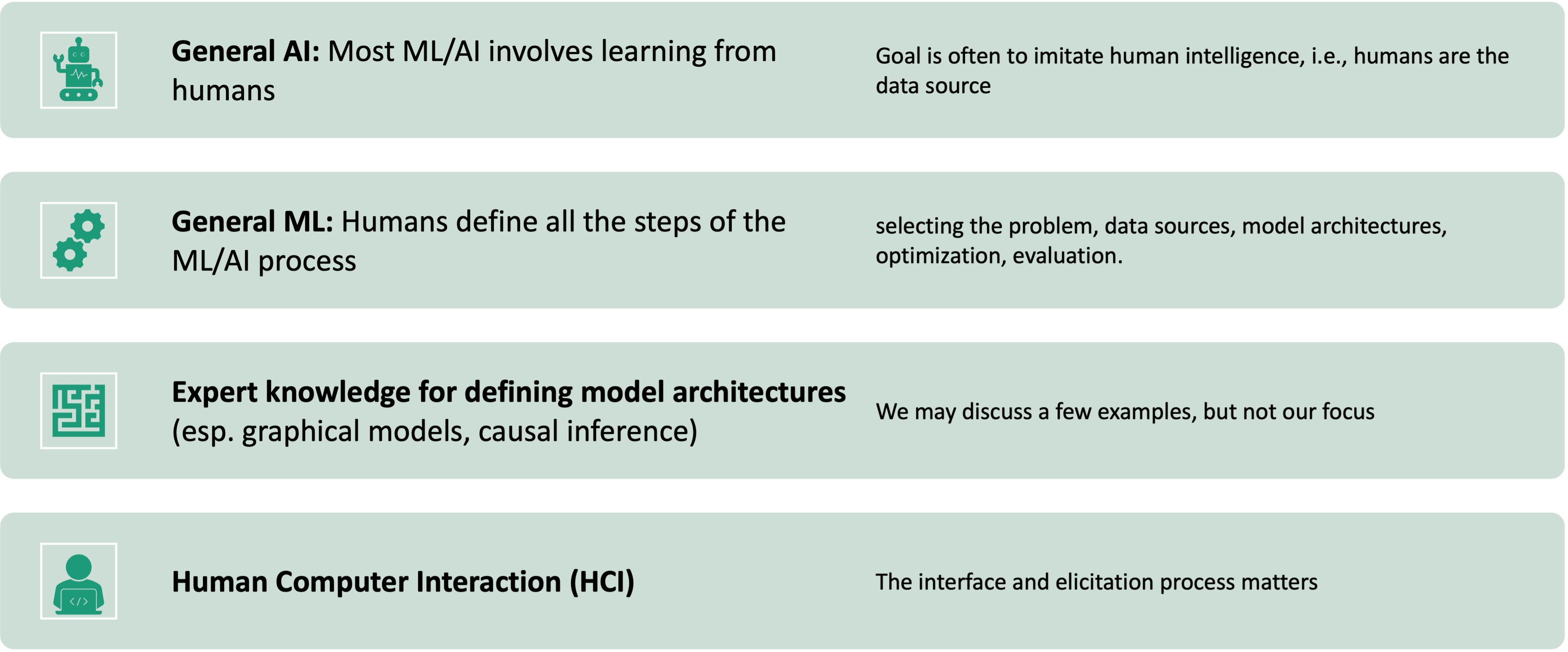
Overview
Feedback can be included at any step of training
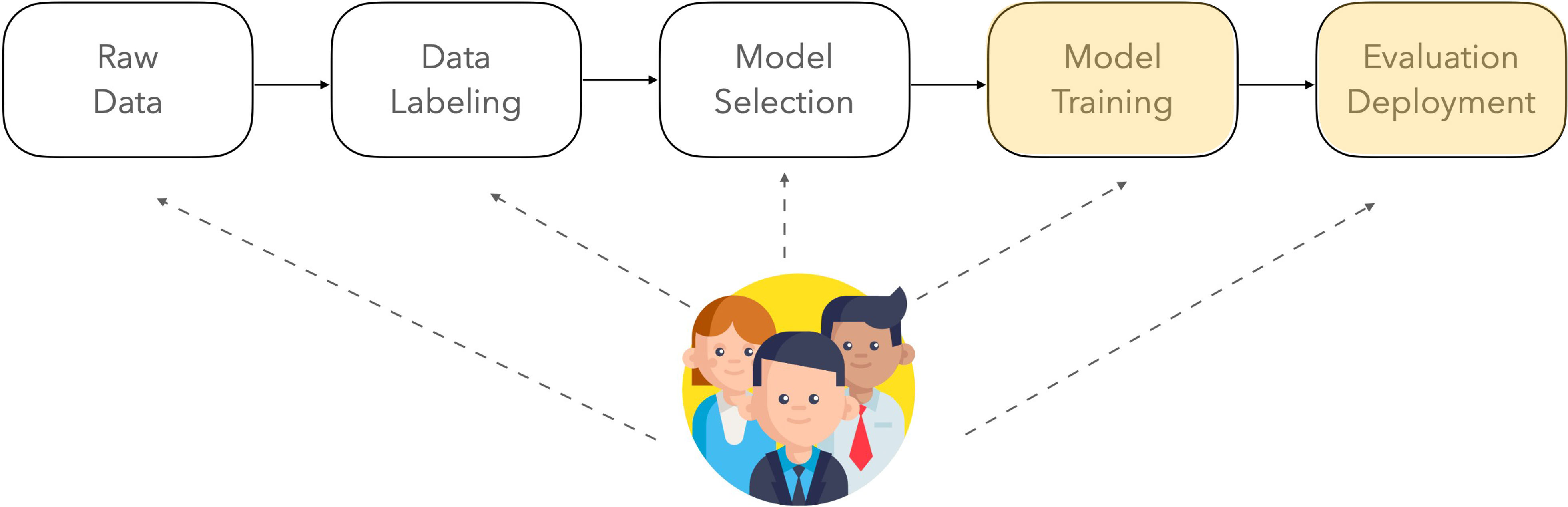
- Slides modified from Diyi Yang.
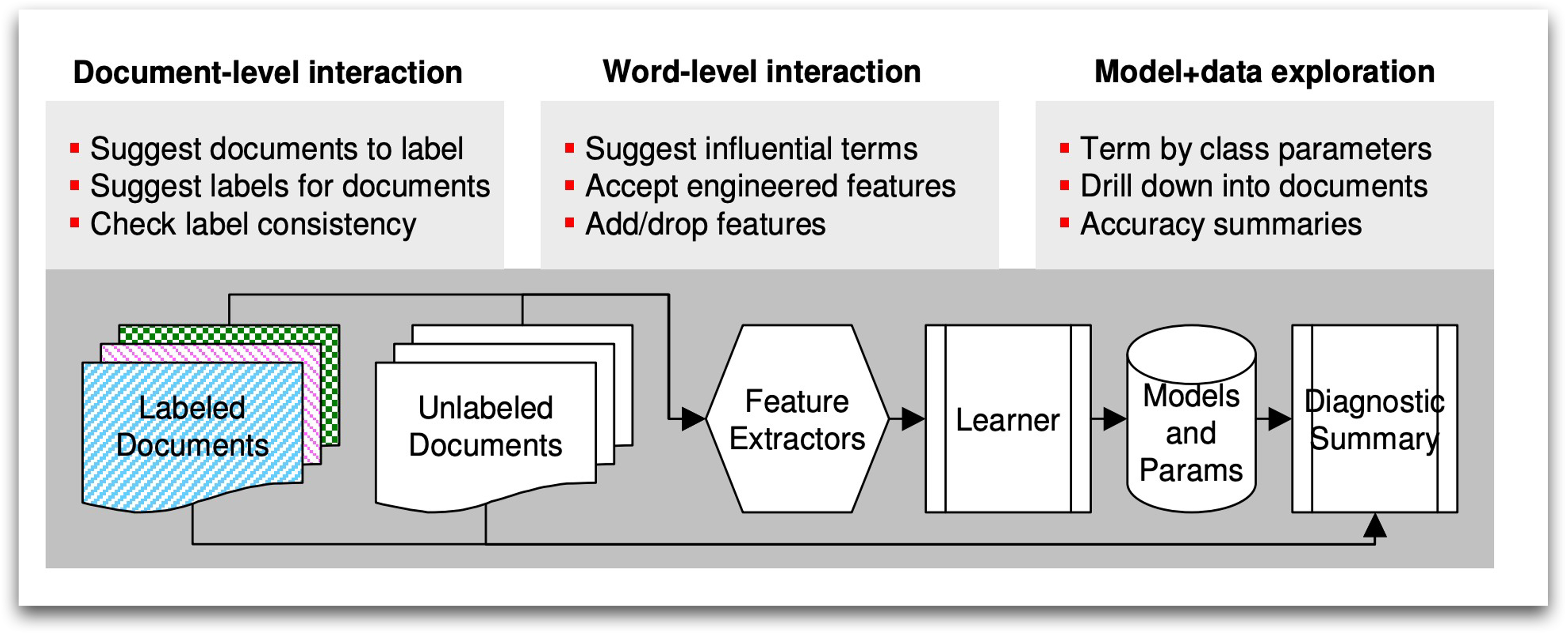
Examples: Natural Languages
Examples: Natural Languages
Builds on research studying human feedback in language
Harpale, Sarawagi, and Chakrabarti (2004)
Examples: Natural Languages
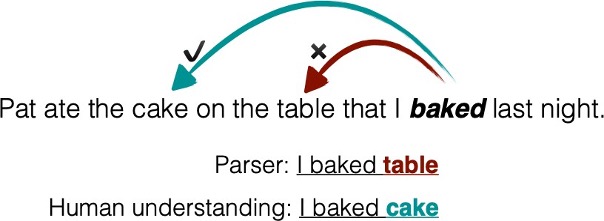
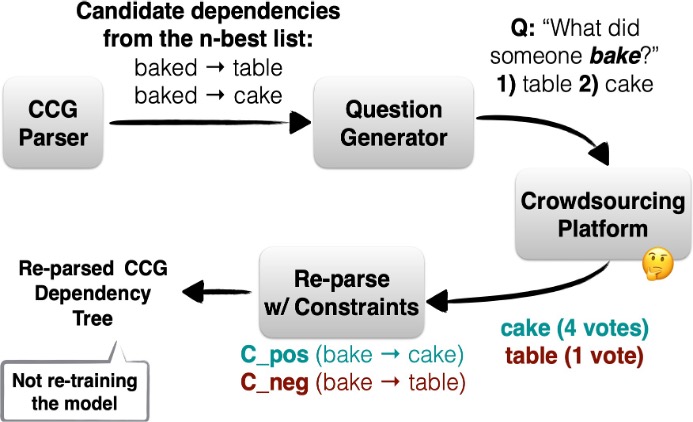
He et al. (2016)
Examples: Natural Languages
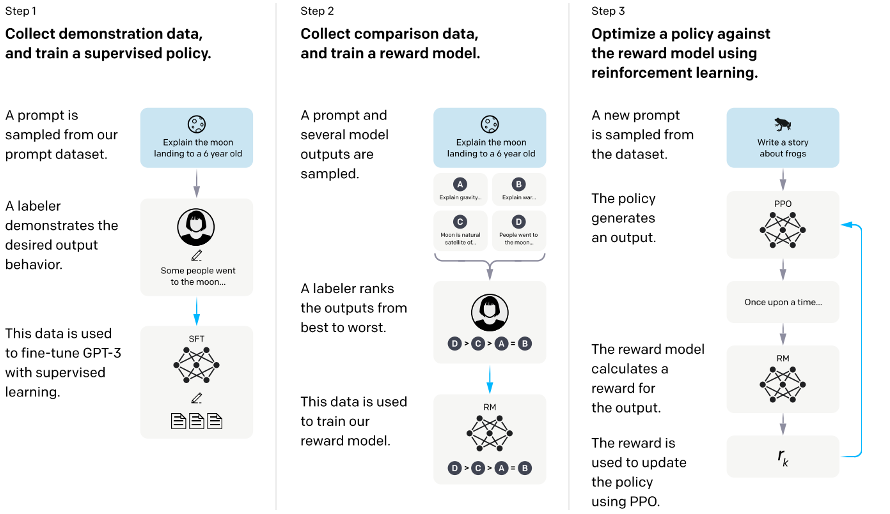
Ouyang et al. (2022)
Examples: Natural Languages
OpenAI Experiments with RLHF
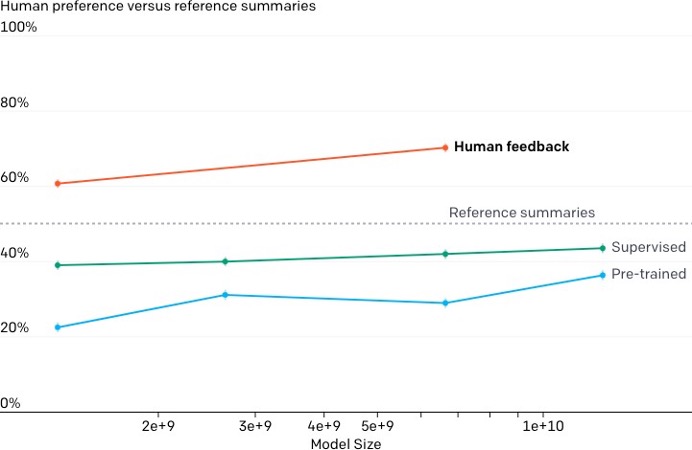

Stiennon et al. (2020)
Motivation
We have not figured out how to do it quite right, or we need new approaches
- Human preferences data reflects human biases, such as length and authoritative tone.
- Human preferences can be unreliable, e.g., reward hacking in RL.


Ethical Issues
- Labeling often depends on low-cost human labor
- The line between economic opportunity and employment is unclear
- May cause psychological issues for some workers

Ethical Issues
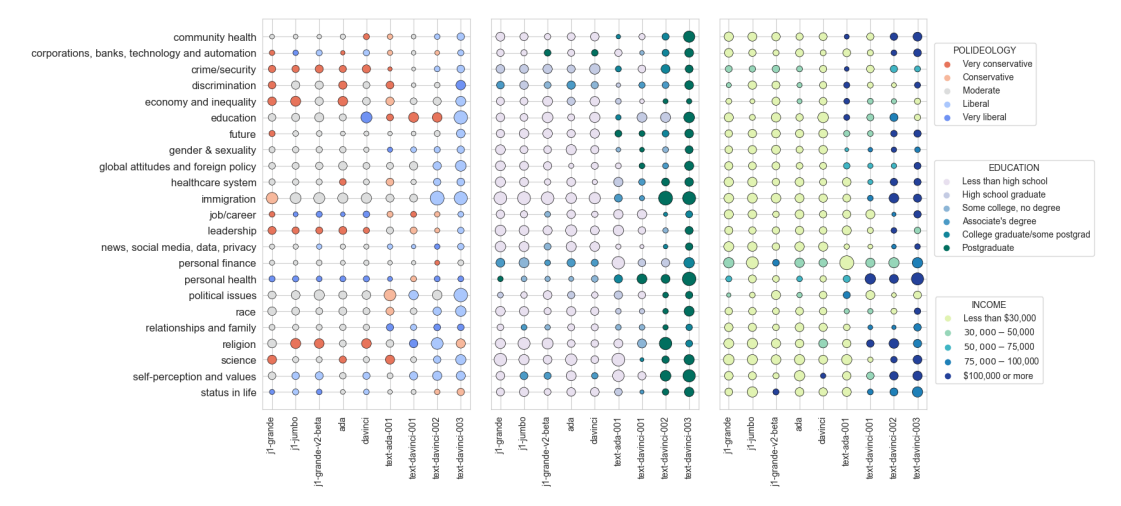
Santurkar et al. (2023)
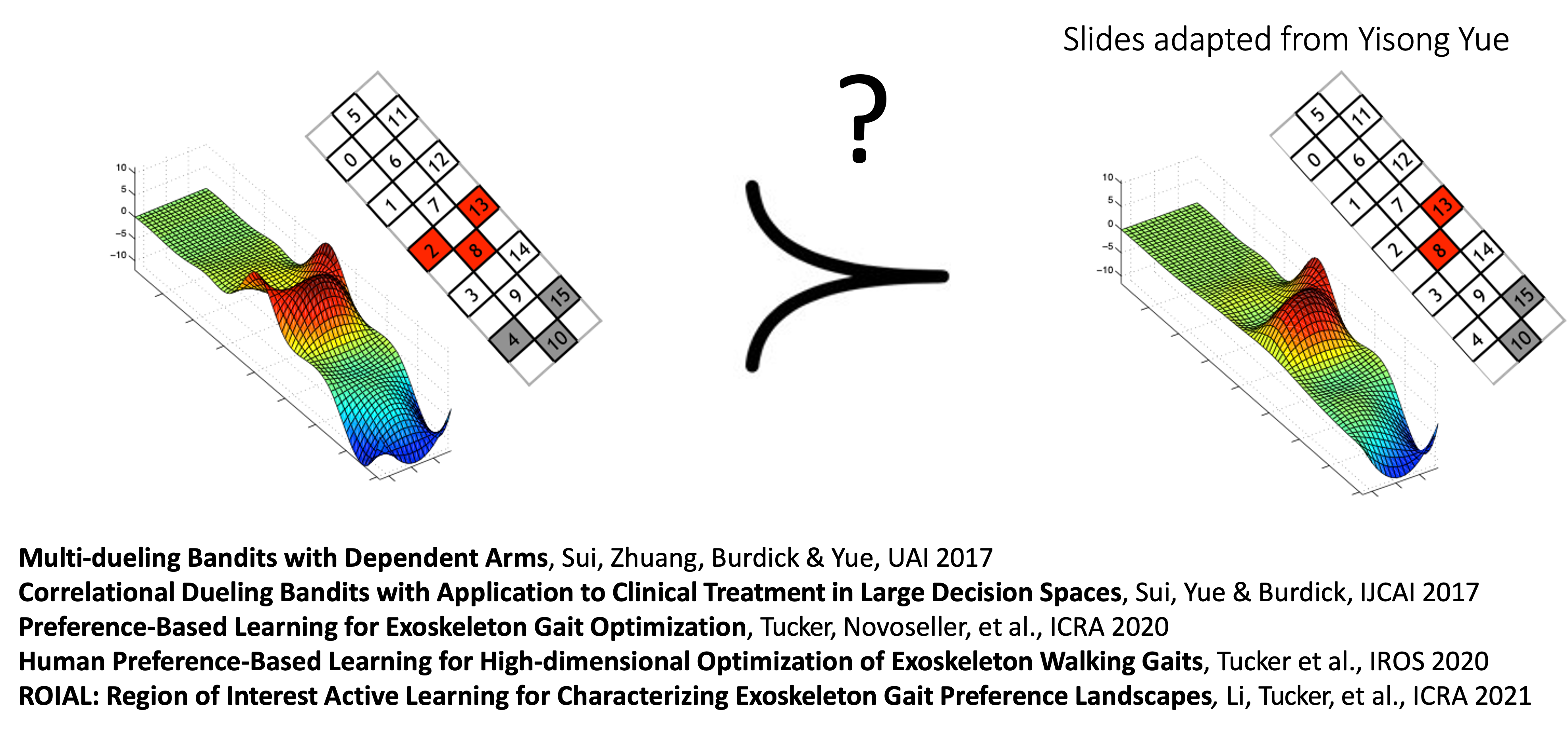
Examples: Dueling Bandits
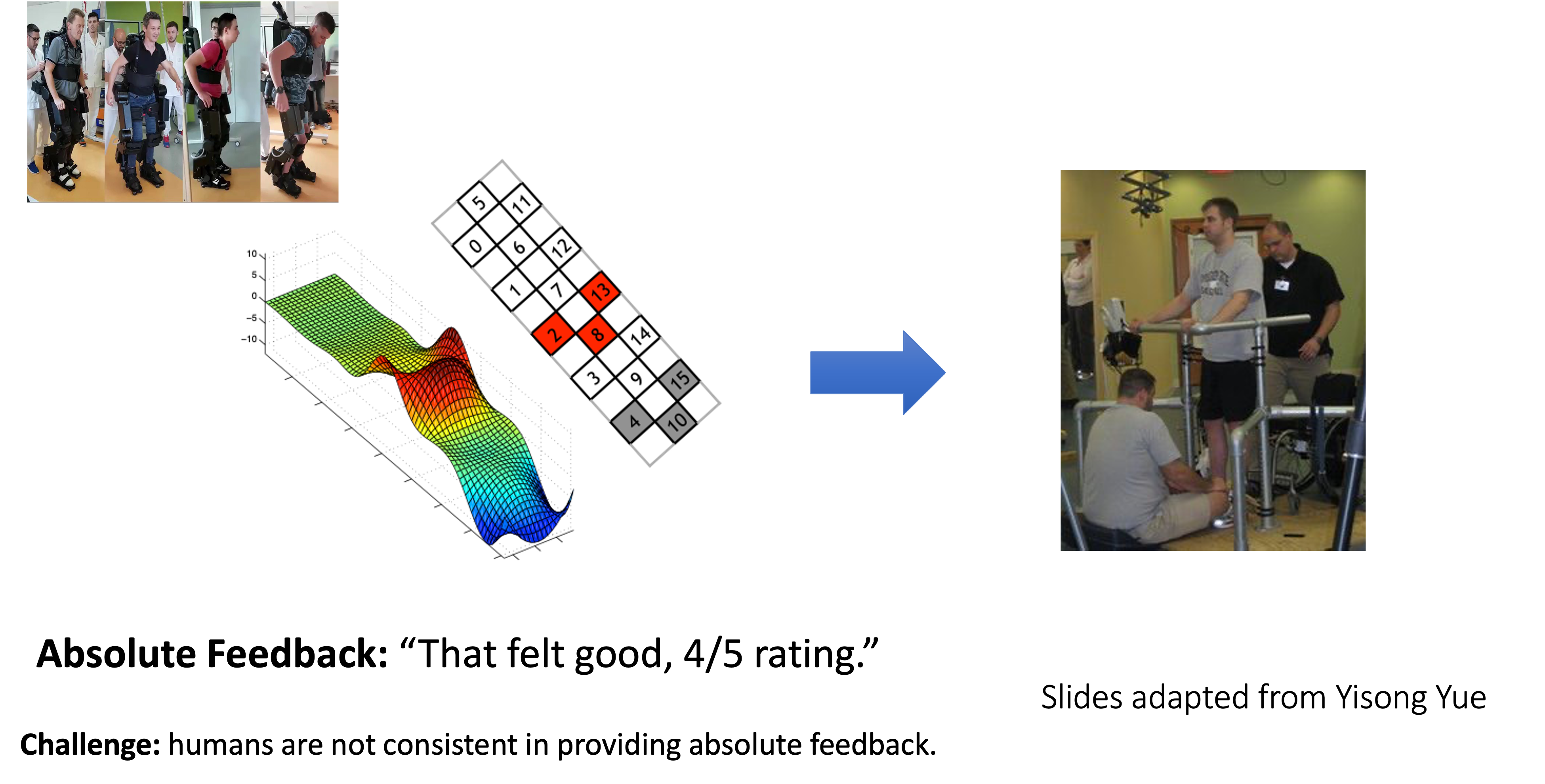
Personalize therapy
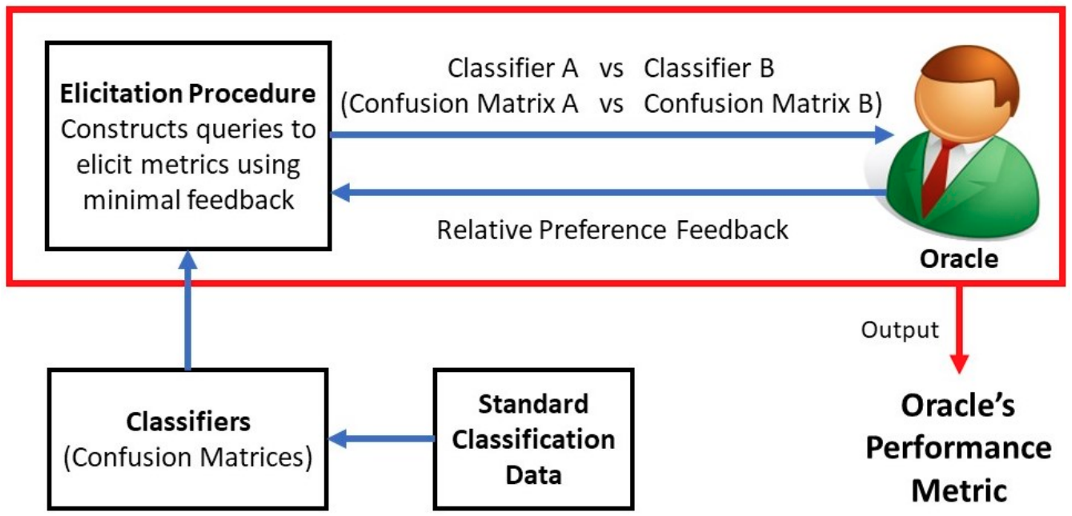
Examples: Metric Elicitation
- Determine the fairness and performance metric by interacting with individual stakeholders (Hiranandani et al. 2019b, 2019a)
- Metric elicitation from stakeholder groups (Robertson, Hiranandani, and Koyejo 2023)
Examples: Metric Elicitation
Why elicit metric preferences?

Examples: Inverse RL
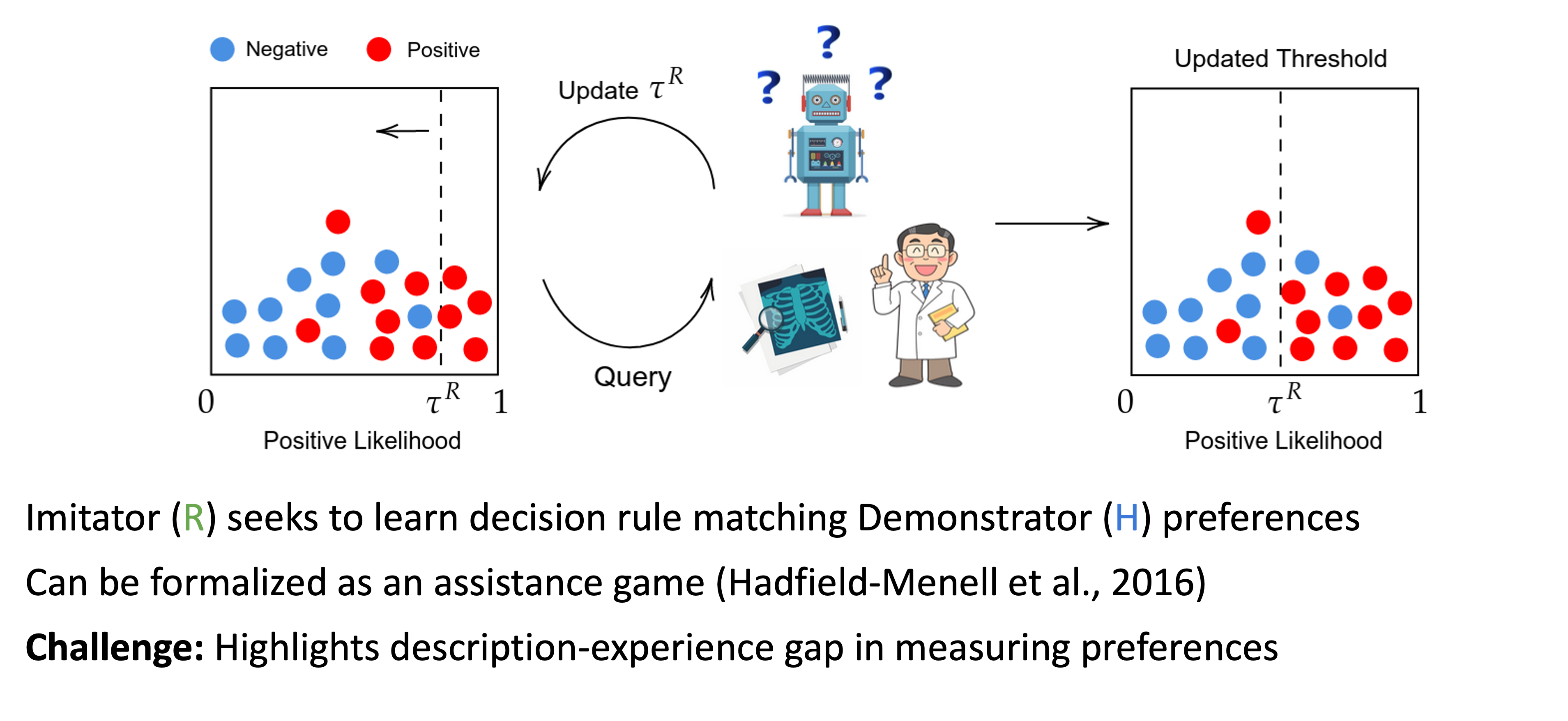
Robertson, Haupt, and Koyejo (2023)
Examples: Recommender Systems

Examples: RLHF
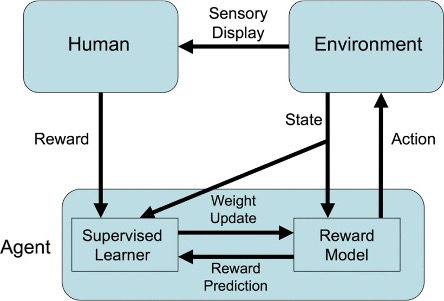
Bradley Knox and Stone (2008)
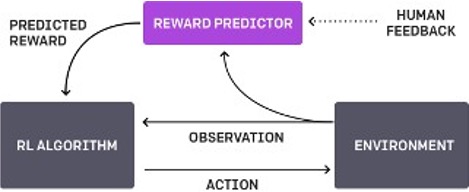
Christiano et al. (2017)
Tradeoffs
Design of tools for eliciting feedback from humans often has to tradeoff several factors

Key Assumptions & Discussion

Welcome to CS329H!
![]()